前言:为什么有状态管理这个东西
前端要管理很多奇奇怪怪的状态,和与之相关的逻辑代码:
- 一个应用一般都有服务器响应的数据吧?响应状态是否要管理?响应后的处理结果也要管理
- 数据多了, 肯定要有缓存吧?缓存数据也要进行管理
- 本地也会产生数据返回给服务器吧?这些数据没有返回给服务器存储的时候也要在前端管理
- 本身前端要管理的UI状态(比如控制渲染的boolean、全局的或非全局的状态、激活的路由、被选中的标签、分页器等等···)
前端技术栈从命令式到声明式:
从早期的jQuery命令式编程编辑管理DOM到Angular、React、Vue陆续推出,写代码的方式发生了变化。而在复杂应用上的状态管理,光使用框架 / 库本身无法完全做到,比如就像Redux的作者 Dan Abramov 说的:
只有遇到 React 实在解决不了的问题,你才需要 Redux
- “数据驱动”思想与单向数据流的局限
UI= Render(data)的思想随着Vue、React的普及逐渐深入开发者内心。这种写法是更加“modern”也是契合框架/库设计思路的写法。尤其是React里每个组件是“纯函数”,完全受控于props的严苛设计使得“数据流”的概念被抽象和推广
但是单向数据流的严格限制下,虽然保证了“数据驱动视图更新”的设计,但是大型工程里独立组件间相互注册事件形成的网状结构会给debug工作带来的巨大成本。所以“将分散的数据整合起来管理”的中心化状态管理工具才得以出现(所以这是一个提升Developer Experience的工具)
不过归根结底,前端所做的工作抽象起来依旧是以渲染UI为核心的人机交互和与服务端双向沟通。那么UI、前端数据、和服务端数据之间的关系,就是状态管理要做的事情。而为了让UI更加的“可预测”,大部分状态管理工具的概念是相似的:集中管理保存状态和受限的状态共享机制
从Flux说起
Facebook在用React开发的时候就面临了上述的“状态多了React单向数据流管理起来很麻烦”的问题。他们的解决方案是:Flux思想
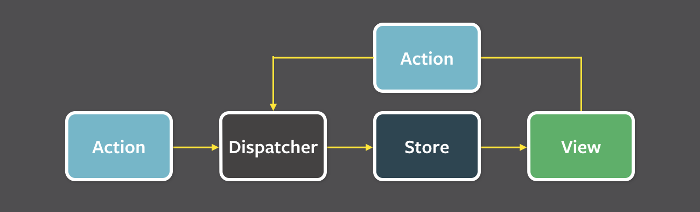
从图中可以看到,Flux的设计也是相当简洁的单向数据流,数据统一到Store里,Action触发Dispatcher使数据变化,数据驱动视图发生改变。任何状态的变更离不开Action的发起和Dispatcher的分发。
实际上,Flux是做了一个独立于React props单项数据流传递的另一个“单项数据流模型”,它定义了一套Action -> Dispatcher -> Store的流程规范,并且用注入的方法将Store里保存的数据、监听逻辑包裹进组件里。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
export const ActionTypes = {
INCREMENT: 'INCREMENT',
DECREMENT: 'DECREMENT'
};
import { Dispatcher } from 'flux';
export default new Dispatcher();
import { ActionTypes } from './ActionTypes.js';
import NumDispatcher from './NumDispatcher.js';
export const increment = (caption){
NumDispatcher.dispatch({
type: ActionTypes.INCREMENT,
caption:caption
})
}
export const decrement = (caption) {
NumDispatcher.dispatch({
type: ActionTypes.DECREMENT,
caption:caption
})
}
import NumDispatcher from './NumDispatcher.js'
const values = {
'First': 0,
'Second': 10,
'Third': 30
}
const Store = Object.assign({}, EventEmitter.prototype, {
getValues: function() {
return values
},
emitChange: function() {
this.emit(CHANGE_EVENT);
},
addChangeListener: function(callback) {
this.on(CHANGE_EVENT, callback);
},
removeChangeListener: function(callback) {
this.removeListener(CHANGE_EVENT, callback)
}
})
Store.dispatchToken = NumDispatcher.register((action) => {
if (action.type === ActionTypes.INCREMENT) {
value[action.caption]++;
Store.emitChange();
} else if (action.type === ActionTypes.DECREMENT) {
value[action.caption]--;
Store.emitChange();
}
})
...
class View extends React.component {
onClickIncrementButton() {
Actions.increment(this.props.caption)
}
onClickDecrementButton() {
Actions.decrement(this.props.caption)
}
render() {
const { caption } = this.props;
return (
<div>
<button onClick={this.onClickIncrementButton}>+</button>
<button onClick={this.onClickDecrementButton}>-</button>
</div>
)
}
}
|
但是, Container.createFunctional(component, ...props)的写法会使数据集成在this.state里,而函数式组件式通过props获取的;且多数据间相互依赖导致的一致性的问题、多个store的dispatcher写法问题等等,说明Flux也有一定的提升空间
Redux
Flux是一种设计思想,那么Redux就是设计思想的继承和改进:
- 单一数据源
比起flux有aaaStore、bbbStore的“应用可以拥有多个Store”设计,Redux直接将分散的数据统一到一个Store里。这点和Flux的对比非常强烈,但是如何设计Store的层级和状态结构也是用Redux要考虑的问题。
- state只读
不饿能直接修改state,而要用action去修改state。这点和Flux的精神一脉相承,也是React思路的延申。毕竟UI=render(data)
- 只能用纯函数来修改state(immutable)
纯函数的就是Redux概念中的Reducer,根据Dan自己的说法,Redux的含义就是“Reducer + flux”
Redux解决的Flux遗留问题有很多,最关键的在于数据和处理数据的逻辑是分离开的,所以热替换时不会受到影响。reducer处理后不直接修改state而是返回一个新的state,保证了时间回溯的功能。但设计如此简单的Redux之所以也能有“生态”,是因为它有一套自己的中间件机制。
Redux中的中间件提供的是位于 Action 被发起之后,到达 Reducer 之前的时候
Redux写法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
export const actionTypes = {
INCREMENT: 'INCREMENT',
DECREMENT: 'DECREMENT'
}
import { actionTypes } from './actionTypes.js'
export const increment = (caption) => {
return {
type: actionTypes.INCREMENT,
caption
}
}
export const decrement = (caption) =>{
return {
type: actionTypes.DECREMENT,
caption
}
}
import { actionTypes } from './actionTypes';
export default (state, action) => {
const { caption } = action;
switch(action.type) {
case (actionTypes.INCREMENT): {
return {
...state,
[caption]: state[caption]++;
}
}
case (actionTypes.DECREMENT): {
return {
...state,
[caption]: state[caption]--;
}
}
default:
return state
}
}
import { createStore } from 'redux';
import reducer from './reducer.js';
const initValues = {
'FIRST': 0,
'SECOND': 10,
'THIRD': 30,
}
export default createStore(reducer, initValues);
import store from './store.js';
class View extends React.component {
constructor(props) {
super(props);
this.state = this.getOwnState();
}
getOwnState() {
return {
value: store.getState()[this.props.caption]
}
}
onIncrement() {
store.dispatch(Actions.increment(this.props.caption))
}
onDecrement() {
store.dispatch(Actions.decrement(this.props.caption))
}
onChange() {
this.setState(this.getOwnState());
}
componentDidMount() {
store.subscribe(this.onChange);
}
componentWillUnmount() {
store.unsubscribe(this.onChange);
}
render() {
const value = this.state.value;
const { caption } = this.props;
return (
<div>
<button onClick={this.onIncrement}>+</button>
<button onClick={this.decreaseCount}>-</button>
<span>{ caption } count: { value }</span>
</div>
)
}
}
|
Redux的设计哲学里将可扩展性保持的比较好,所以诸如异步的写法是另外的库’redux-thunk’来做的。
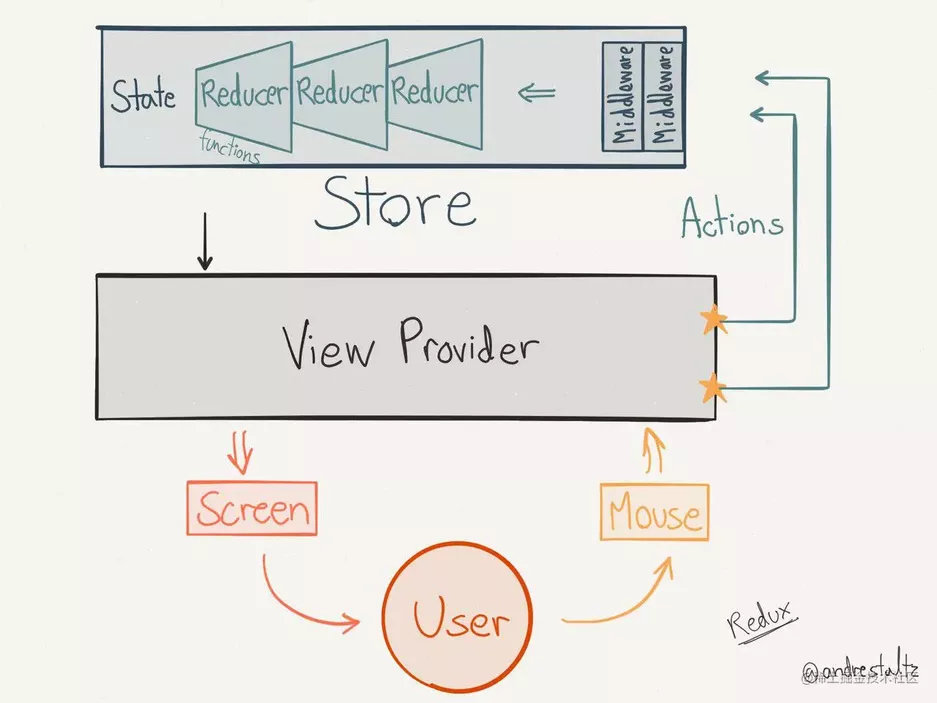
Mobx
MobX 背后的哲学是:
任何源自应用状态的东西都应该自动地获得。
相对于Redux体系,Mobx体系会更加容易理解一些。类似Vue的双向绑定思想,React+Mobx相当于Vue全局作用域下的双向绑定。Mobx引入后带来的双向数据流让写代码可以比较顺畅,但是还会面临应用复杂的情况下难以管理的情况。
Vuex
Vuex的思路也沿袭自Flux,也采取单一状态树,一个应用对应一个Store实例,实例中包含state、actions、mutations、getters、modules
- State 即单一数据源
- Getter 将State过滤后输出
- Mutation vuex中改变State的唯一途径,只能是同步操作,
store.commit()触发
- Action 一些异步操作可以放在Action中,
store.dispatch()触发
- module:用来拆分较大的State为多个Module,每个Module也有自己的state、mutation、action、getter
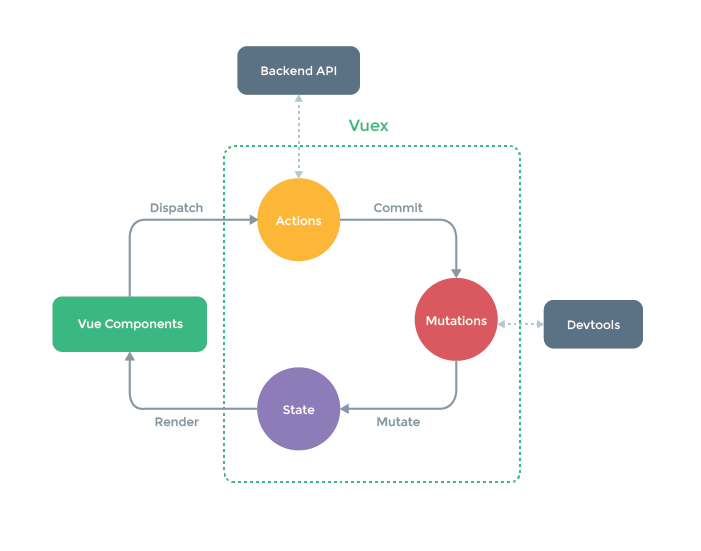
和Redux的“克制”不同的是,Vuex做到的是提供一个解决方案,在项目里直接支持了异步action的写法。并将它和同步写法在API层面上就加以区分。