总有很多历史原因
第一次尝试翻译,原文:THERE’S ALWAYS MORE HISTORY
为什么Vim用hjkl移动上下光标而不用方向键?
常规解释:为了手指保持在一行上
历史原因:Bill Joy在ADM-3A上开发了vi,而ADM-3A没有专门的箭头键。

看ADM键盘,箭头键是放在hjkl键上的,因此,Joy设计vi时也应用了同样的的逻辑,也自然沿用到了Vim
更深度的历史:还是很奇怪,为什么ADM用hjkl当作方向键,而不是其他字母呢?
要回答这个问题,要看1967年版本的ASCII码表:
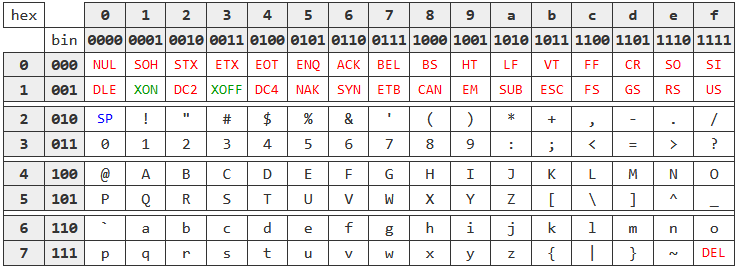
每个字符是七个bit组成的,前32个字符是‘控制字符’,对计算机通信比较重要,但并不是实际的字母,用QWERTY布局制成的键盘需要在这样的布局上保证能够输入这些字符。为了解决这个问问题,ADM的设计者引入了一个额外的‘ctrl’键,将输入从实际的字母更换成控制字符。
按住‘ctrl’ 按键的第六位和第七位最高位会清零,如果要使用退格控制字符,就直接按住ctrl + H / ^ H,就会转换100 1000为000 1000,同样,对于行分隔符,需要按 ctrl + J / ^ J
翻阅ADM手册,我们会发现ADM的“退格键”的含义是“向左移动光标”而不是删除当前字符。在已经将^ H和^ J用作左和下的情况下,将^ K和^ L变成向上和向右就很合适。这意味着ADM用户在使用hjkl作为导航,而Bill Joy开发Vi也是遵循了这个先例。
(译者题外话:很多人使用Vim时会发现esc键作为退出‘编辑模式’的按键其实非常难按到,这是因为ADM的esc是在Q键的旁边,而不是非常远的键盘左上角,因此会有很多人将esc改键到tabs或caps lock键)
为什么JS的月份从0到11而不是1到12?
常规解释:因为这样数组索引会更简单,你需要的是月份的名字而不是序号。你有一个月份名的数组并用data.getMonth()来编索引
历史原因:这是与Java兼容的方式,也是与C兼容的方式。
更深度的历史:那么C为什么要这么做呢?还有为什么除了月份的天数之外都是从0开始为索引?
ANSI C89标准首先正式确定了tm_date结构,直到今天都没有改动,这项标准在C问世后17年确立,让各种各样的Unix标准统一。如果我们回顾Unix历史,可以发现在最早的<ctime.c>样例是没有用结构体的,而是用了一个数组来存储
1 | |
ctime将一天中的时间存储为 秒-分-时(SMH),但是显示是时-分-秒(HMS),这样特殊的处理在实际使用中是有意义的,Unix 5只用这段数据展示时间给用户
1 | |
我注释了一些比较有意思的代码行,我们在(a)处第一次用到存储的月份,开发者没有把所有月份的名称存储在一个数组里,而是把每个月的三个字符的缩写存储在单个字符串中,然后把月份号作为指针算法的一部分来获取实际需要的三个字节。
然后通过指针地址递减三次来获得日期(b),然后获得HMS日期(c) 这样,将其存储为SMH可以节省额外的显式跳转(可以通过向后迭代获得),他们利用了字段作为数组的元素存储,在内存里是紧挨着的特性
曲折的算法告诉我们他们在想尽办法做优化,这是因为Unix的第一个版本实在在PDP-7上开发的,1970年代一台像样的计算机也只有几千字节的内存,如果将所有月份名都存储在内存里,那几乎要占用总内存的10%!
因此,开发者为了尽可能少的使用内存和cpu,他们选择用指针算法来做。使用索引为0的月份要比从1开始的算法更容易实现,另一方面,除了显示给用户看,他们不会使用月份里的天数,因此以可以直接表示的方式存储
该解释还解释了结构上的一个微小的不一致:MDAY(月份的天)从1开始,而YDAY(年份的天)从0开始。这和“便于计算 vs 便于显示”的对立是保持一致的,因为从“年份的天”是从不会给用户展示的,它只用于计算夏令时的开始时间。
这些解释仍然是不完整的。才两层历史,我们可以更深入研究。
对于hjkl问题,我们可以问为什么以这种方式设计ASCII表。对于tm_date问题,我们可以找比较早版本的Unix,看它们在汇编里做的工作,或者直接与开发人员联系。甚至那也不是最后的一层。我们可以随时往前看,越来越深挖历史。
但是就本文而言,这两层就足够了。通过两层,我们可以看到研究历史的一个共同模式:找答案和解释之间的区别。当被问及“为什么是这样”时,大多数人都会给出“事后”的合理解释。他们看到现在,倒推以这种方式会“更好”的原因。但如果稍微回看过去,就会发现“事情是这样的,因为本来就是这样”。如果你回看得更远一些,你就会发现是什么让它变成这个样子。
历史的第一层和第二层之间的差异构成了陷阱。人们看到了第一层就认为这是全部,这让历史显得无关紧要。而且即使意识到它还有更多内容,但是挖掘每一层要比之前花费更多的精力:搜索到Bill Joy使用ADM-3A机器是很快的,但是找到更深的原因,我花了两个小时。
还有一些历史层级的例子:为什么现代语言用=等号来进行分配?第一层是“因为C是这么干的”,第二层是跟踪从ALGOL到C的语言发展链。为什么这么多的面试官问链表问题?第一层是“打开面试的起手式”,第二层涉及阅读数百条Usenet旧帖子并采访退休的程序员。
但这些努力都是值得的。深入研究第二层可以使我们更多地了解上下文以及事物之所以如此的原因。我不否认有些谜题是很难,但解决掉它带来的快乐也无法拒绝:失落的知识被找回来的感觉。
感谢Lito Nicolai和Alex Koppel的反馈。我在时事通讯上分享了这篇文章的初稿。如果您喜欢我的作品,点一个订阅吧?
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!